Apache Hadoop is a distributed system with a number of key components of which a few are important to understand:
-
YARN, which is often referred to as the 'operating system' of Hadoop. YARN is the managing entity which assigns resources to running a specific job or task.
-
HDFS, which is the Hadoop Distributed File System. This is the location where data is located, but also the place where executables are often shared so that a distributed process can be picked up on many nodes in the cluster.
-
Namenode, is a dedicated node in the cluster which deals with HDFS and distribution of data to other nodes, so-called datanodes.
In addition, the DataCleaner Hadoop support is built using Apache Spark, which is a data processing framework that works with Hadoop as well as other clustering technologies. A few important concepts of Apache Spark are useful to understand for DataCleaner's deployment on Hadoop:
-
Cluster manager, which is the component that negotiates with the cluster - for instance Hadoop/YARN. From the perspective of Apache Spark, YARN is a cluster manager.
-
Driver program, which is the program that directs the cluster manager and tells it what to do. In Apache Spark for Hadoop you have two choices: To run the Driver program as an external process ('yarn-client') or to run the Driver program as a process inside YARN itself ('yarn-cluster').
-
Executor, which is a node in a Spark cluster that executes a partition (chunk) of a job.
In the top-part of the below image you see Hadoop/YARN as well as Apache Spark, and how they are componentized.
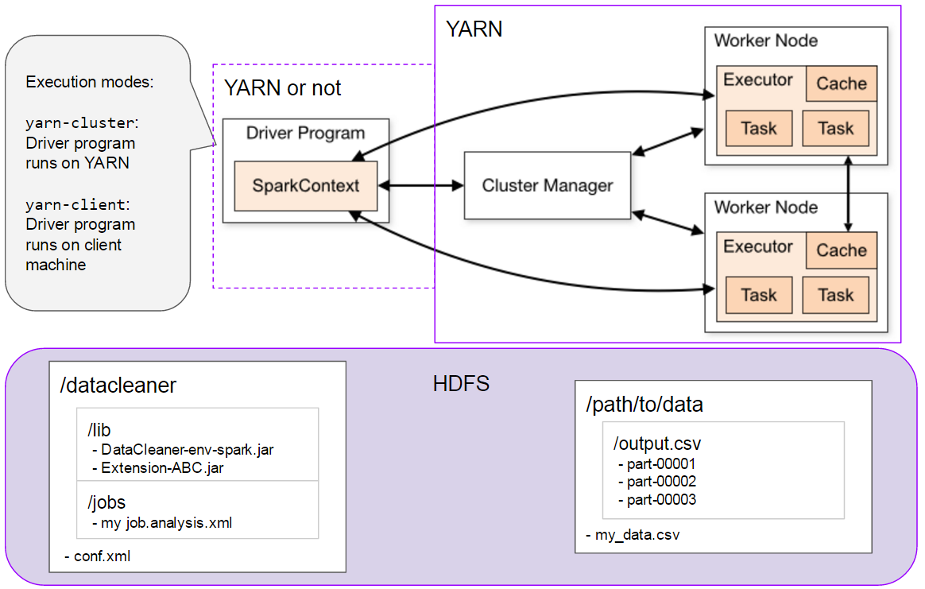
In the lower part of the image you see DataCleaner's directory structure on HDFS. As you can see, the usual configuration and job files are used, but placed on HDFS. A special JAR file is placed on HDFS to act as executable for the Apache Spark executors.