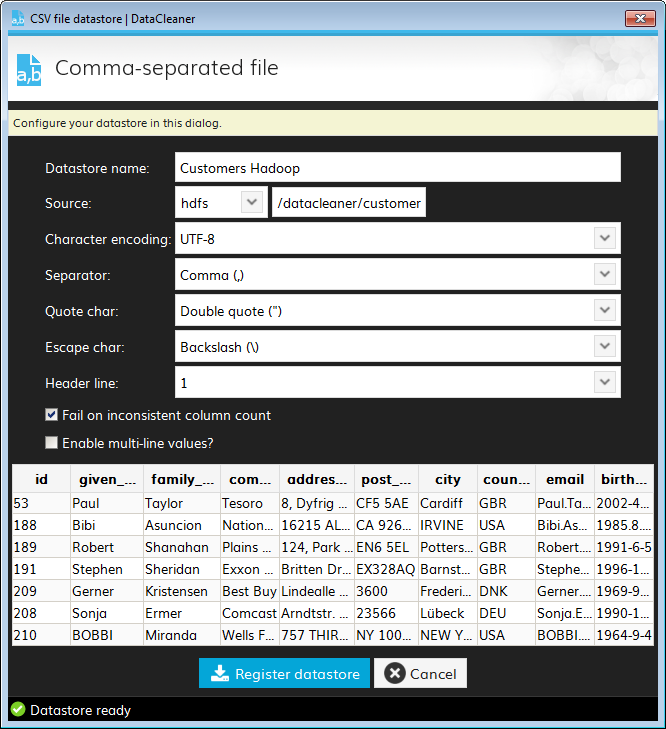
Within DataCleaner desktop you can process CSV datastores located on HDFS.
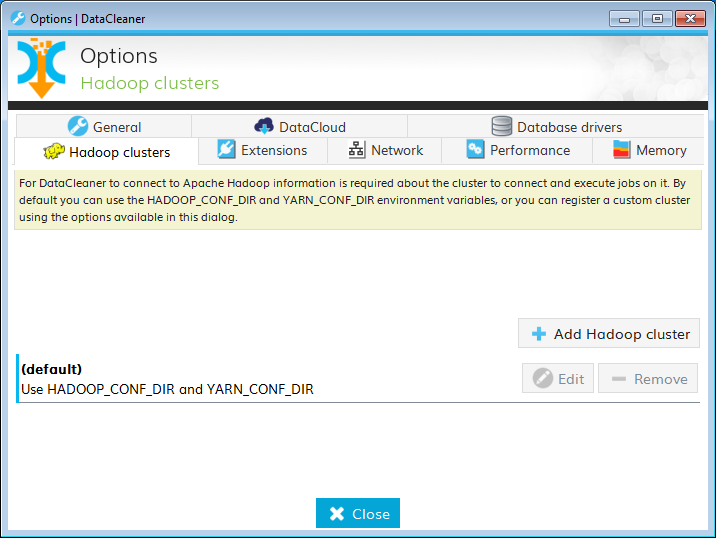
To be able to execute jobs from DataCleaner desktop on a Hadoop Cluster you have a number of configuration options which are managed in the Hadoop clusters tab in the Options dialog.
-
Default
By default DataCleaner uses the HADOOP_CONF_DIR and YARN_CONF_DIR environment variables to determine the location of the Hadoop/Yarn configuration files such as core-site.xml and yarn-site.xml.
-
Using configuration directory
By clicking the Add Hadoop cluster button and then selecting the Using configuration directory you can register additional Hadoop clusters by adding locations which contain Hadoop/Yarn configuration files.
-
Using direct namenode connection
By clicking the Add Hadoop cluster button and then selecting the Using direct namenode connection you can registerd additional Hadoop clusters using their file system URI (e.g. hdfs://bigdatavm:9000/).
If you have added additional Hadoop clusters, when selecting a file on HDFS, it first opens a dialog where you can select from which Hadoop custer you want to select a file.
When registering a CSV datastore you have the option to select "hdfs" as scheme for the source of the CSV. In the path field you can either fill in an absolute path, including the scheme, e.g. hdfs://bigdatavm:9000/datacleaner/customers.csv or the relative path to a file on HDFS, e.g. /datacleaner/customers.csv. Note that a relative path only works when you have set the HADOOP_CONF_DIR or YARN_CONF_DIR environment variables (see Setting up Spark and DataCleaner environment).