The pattern finder is one of the more advanced, but also very popular analyzers of DataCleaner.
Here is a screenshot of the configuration panel of the Pattern finder:
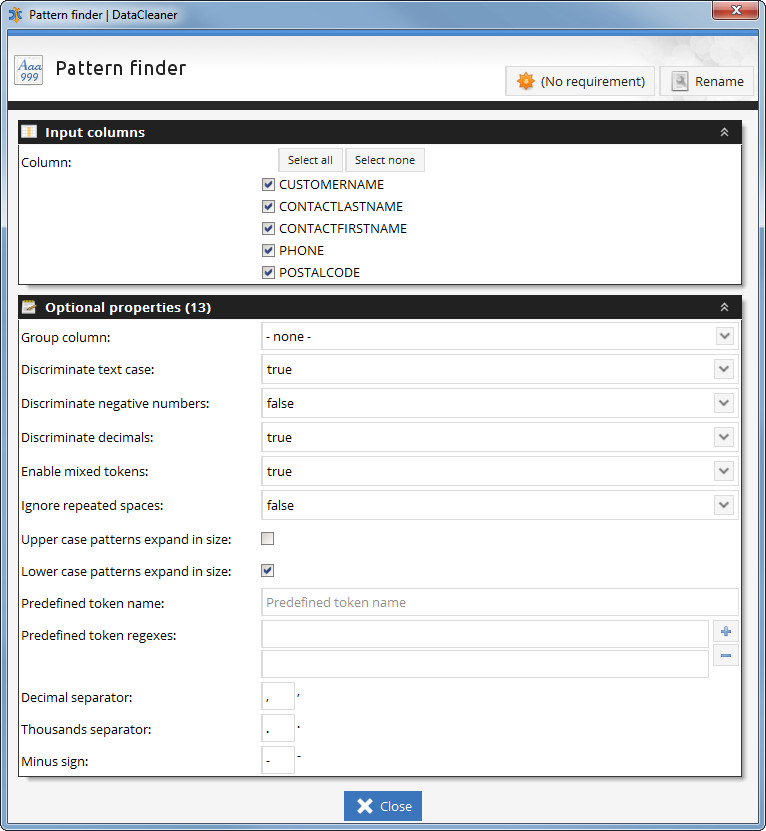
From the screenshot we can see that the Pattern finder has these configuration properties:
Table 5.2. Pattern finder properties
| Property | Description |
|---|---|
| Group column | Allows you to define a pattern group column. With a pattern group column you can separate the identified patterns into separate buckets/groups. Imagine for example that you want to check if the phone numbers of your customers are consistent. If you have an international customer based, you should then group by a country column to make sure that phone patterns identified are not matched with phone patterns from different countries. |
| Discriminate text case | Defines whether or not to discriminate (ie. consider as different pattern parts) based on text case. If true "DataCleaner" and "datacleaner" will be considered instances of different patterns, if false they will be matched within same pattern. |
| Discriminate negative numbers | When parsing numbers, this property defines if negative numbers should be discriminated from positive numbers. |
| Discriminate decimals | When parsing numbers, this property defines if decimal numbers should be discriminated from integers. |
| Enable mixed tokens |
Defines whether or not to categorize tokens that contain both letters and digits as "mixed", or alternatively as two separate tokens. Mixed tokens are represented using questionmark ('?') symbols. This is one of the more important configuration properties. For example if mixed tokens are enabled (default), all these values will be matched against the same pattern: foo123, 123foo, foobar123, foo123bar. If mixed tokens are NOT enabled only foo123 and foobar123 will be matched (because 123foo and foo123bar represent different combinations of letter and digit tokens). |
| Ignore repeated spaces | Defines whether or not to discriminate based on amount of whitespaces. |
| Upper case patterns expand in size | Defines whether or not upper case tokens automatically "expand" in size. Expandability refers to whether or not the found patterns will include matches if a candidate has the same type of token, but with a different size. The default configuration for upper case characters is false (ie. ABC is not matched with ABCD). |
| Lower case patterns expand in size |
Defines whether or not lower case tokens automatically "expand" in size. As with upper case expandability, this property refers to whether or not the found patterns will include matches if a candidate has the same type of token, but with a different size. The default configuration for lower case characters is true (ie. 'abc' is not matched with 'abc'). The defaults in the two "expandability" configuration properties mean that eg. name pattern recognition is meaningful: 'James' and 'John' both pertain to the same pattern ('Aaaaa'), while 'McDonald' pertain to a different pattern ('AaAaaaaa'). |
| Predefined token name | Predefined tokens make it possible to define a token to look for and classify using either just a fixed list of values or regular expressions. Typically this is used if the values contain some additional parts which you want to manually define a matching category for. The 'Predefined token name' property defines the name of such a category. |
| Predefined token regexes | Defines a number of string values and/or regular expressions which are used to match values against the (pre)defined token category. |
| Decimal separator | The decimal separator character, used when parsing numbers |
| Thousand separator | The thousand separator character, used when parsing numbers |
| Minus sign | The minus sign character, used when parsing numbers |