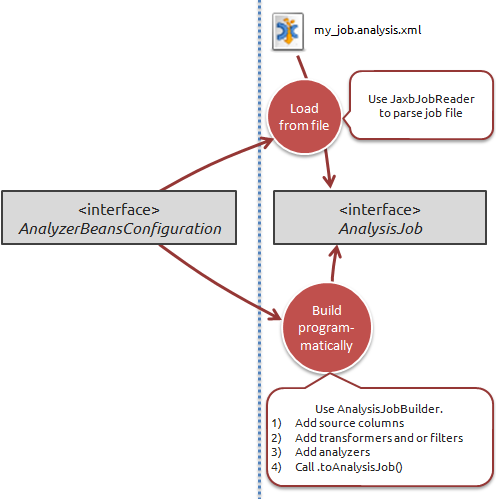
Like with the configuration, we can choose to either load the job we want to run from a file, or build it programmatically.
Let's start by simply loading a job from a file. We'll need to use the JaxbJobReader class:
InputStream inputStream = new FileInputStream("my_job.analysis.xml");
JaxbJobReader jobReader = new JaxbJobReader(configuration);
AnalysisJob analysisJob = jobReader.read(inputStream);
Note that this is the 'vanilla' case. You can also use the JaxbJobReader to read metadata about a job, and even to read a job 'as a template', which makes it possible to instantiate the job with certain replacements. For an example of how this functionality is used in DataCleaner's desktop application, see the template jobs section.
The other way of producing a job is to build it programmatically. This is quite involved process that varies quite a lot depending on what kind of job you want to build. But the API has been designed to make it as easy as possible.
To give an overview of the API, consider this list of important classes:
-
AnalysisJobBuilder : Represents a mutable job that is being built. This builder object contains source columns of the job, and all the components that consume source columns (or sometimes transformed columns).
-
TransformerComponentBuilder , FilterComponentBuilder , and AnalyzerComponentBuilder : , represents mutable components of the job that is being built. These can each have configuration properties, filter requirements, input and output columns.
Tip
Be aware of the unfortunate similarity between the 'AnalyzerComponentBuilder' class name and the 'AnalysisJobBuilder' class name. To rid the confusion, remember that the 'analysis' represents the full scope of the job, whereas an 'analyzer' is just a single active part ('component') of the job.
Let's see an example of building a job programmatically. And to ensure that we don't miss important insights, we'll make it a fairly non-trivial job with both filters, transformers and analyzers. The job will encompass:
-
Three source columns from the datastore 'my database': Name, Age and Company_name.
-
All records where 'Company_name' is null will be inserted into the datastore called 'my CSV file'. In the CSV file the columns are called 'fullname' and 'age_years'.
-
All records where 'Company_name' isn't null will 1) have their working address looked up in another table of the database, and 2) the name and the working address will be passed on to a 'Pattern finder' analyzer.
Datastore myDatabase = configuration.getDatastoreCatalog().getDatastore("my database");
Datastore myCsvFile = configuration.getDatastoreCatalog().getDatastore("my CSV file");
AnalysisJobBuilder builder = new AnalysisJobBuilder(configuration);
builder.setDatastore(myDatabase);
builder.addSourceColumns("public.persons.Name","public.persons.Age","public.persons.Company_name")
InputColumn<?> nameColumn = builder.getSourceColumnByName("Name");
InputColumn<?> ageColumn = builder.getSourceColumnByName("Age");
InputColumn<?> companyColumn = builder.getSourceColumnByName("Company_name");
// add a filter to check for null 'company'
FilterComponentBuilder<NullCheckFilter> nullCheckBuilder = builder.addFilter(NullCheckFilter.class);
nullCheckBuilder.addInputColumn(companyColumn);
// add a InsertIntoTable analyzer to write the records without a company to the csv file
AnalyzerComponentBuilder<InsertIntoTableAnalyzer> insertBuilder = builder.addAnalyzer(InsertIntoTableAnalyzer.class);
insertBuilder.addInputColumns(nameColumn, ageColumn);
insertBuilder.setConfiguredProperty("Datastore", myCsvFile);
insertBuilder.setConfiguredProperty("Columns", new String[] {"fullname","age_years"});
insertBuilder.setRequirement(nullCheckBuilder.getOutcome(NullCheckFilter.Category.NULL));
// add a lookup for the company working address
TransformerComponentBuilder<TableLookupTransformer> lookupBuilder =
builder.addTransformer(TableLookupTransformer.class);
lookupBuilder.addInputColumn(companyColumn);
lookupBuilder.setConfiguredProperty("Datastore", myDatabase);
lookupBuilder.setConfiguredProperty("Schema name", "public");
lookupBuilder.setConfiguredProperty("Table name", "companies");
lookupBuilder.setConfiguredProperty("Condition columns", new String[] {"name"});
lookupBuilder.setConfiguredProperty("Output columns", new String[] {"address"});
lookupBuilder.setRequirement(nullCheckBuilder.getOutcome(NullCheckFilter.Category.NOT_NULL));
// reference the 'working address' column and give it a proper name
MutableInputColumn<?> addressColumn = lookupBuilder.getOutputColumns().get(0);
addressColumn.setName("Working address");
// add the Pattern finder analyzer
PatternFinder patternFinder = jobBuilder.addAnalyzer(PatternFinder.class);
patternFinder.addInputColumns(nameColumn, addressColumn);
// validate and produce to AnalysisJob
AnalysisJob analysisJob = jobBuilder.toAnalysisJob();
Things to note from this example:
-
Notice how the filter requirements are set up using the .setRequirement(...) method on the succeeding components.
-
There aren't any explicit filter requirements set on the 'Pattern finder' analyzer. This isn't necesary since it depends on a transformed input column ('Working address') which itself has the requirement. DataCleaner will figure out the transitive requirements automatically.
-
One piece of 'magic' is how to set the properties of the components correctly. We can see that we call .setConfiguredProperty(String,Object) , but not how to figure out what to pass as arguments. There are two proper ways to figure this out...
-
You can use DataCleaner's command line to list all components of a specific type, e.g.:
> DataCleaner-console.exe -list ANALYZERS ... name: Insert into table - Consumes 2 named inputs Input columns: Additional error log values (type: Object) Input columns: Values (type: Object) - Property: name=Column names, type=String, required=true - Property: name=Datastore, type=UpdateableDatastore, required=true ...
-
Or you can simply open up the component class in an IDE to inspect it's @Configured properties. For instance, if we look at InsertIntoTableAnalyzer.java we'll see:
... @Inject @Configured @Description("Names of columns in the target table.") @ColumnProperty String[] columnNames; @Inject @Configured @Description("Datastore to write to") UpdateableDatastore datastore; ...From these fields we can infer that there will be two configured properties, 'Column names' and 'Datastore'.
-
Either way we do it, we now have an AnalysisJob with the variable name 'analysisJob'. Then we can proceed to actually executing the job.